在 windows 使用 conda 環境搭建 OCR 訓練環境
發佈於 April 15, 2023
說明
- 使用
PaddlePaddle平台中的模組**PP-OCRv3**作為示範,詳細訓練方法請參閱官方文檔。 - 以下實作是在windows作業系統,並使用搭配使用
NVIDIA GeForce RTX 2080進行環境建置。 - 若在訓練過程中有遇到
numpy問題請搜尋可匹配的版本號,並重新安裝numpy。
實作
建立訓練環境
-
新建
conda環境。conda create -n ocr python=3.8 conda activate ocr -
到官方點選下載選項選擇與本機匹配的
Cuda配置,並用產生的指令去安裝paddlepaddle-gpu。python -m pip install paddlepaddle-gpu==2.3.2.post101 -f https://www.paddlepaddle.org.cn/whl/windows/mkl/avx/stable.html -
驗證有無成功安裝
paddlepaddle-gpu。import paddle paddle.utils.run_check() # 如果有會跳出成功字樣 -
安裝
PaddleOCR# Clone PaddleOCR(Inference+training) git clone https://github.com/PaddlePaddle/PaddleOCR cd PaddleOCR pip install -r requirements.txt -
安裝
PPOCRLabelpip install PPOCRLabel
標註資料
-
在
PaddleOCR專案中新增資料夾,資料集結構如下,此範例將訓練集與測試集當作同一個來源。. └── train_data ── data ├ ... ├── image0.jpg └── image1.jpg -
啟動標註軟體
conda activate ocr PPOCRLabel -
開始標記。標記完成後要存取
Label.txt和crop_img資料,如下圖綠色區域。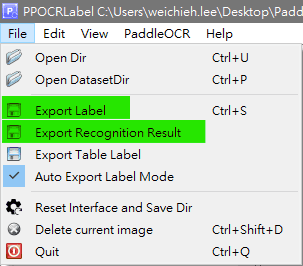
-
最終數據集結構會類似如下。
. └── train_data ── data ├ ... ├── image0.jpg ├── image1.jpg ├── Label.txt ├── rec_gt.txt └── crop_img
建立 Det 訓練設定
-
點擊此連結。下載預訓練模型。
- 這邊下載
en_PP-OCRv3_det模型。config檔案參照PaddleOCR/configs/det/ch_PP-OCRv3/ch_PP-OCRv3_det_student.yml。
- 這邊下載
-
配置模型以及config路徑。
. └── pretrain_models ── en_PP-OCRv3_det_distill_train ├── best_accuracy.pdparams ├── student.pdparams └── config.yml -
調整
config.yml內容Global: pretrained_model: ./pretrain_models/en_PP-OCRv3_det_distill_train/student . . Train: dataset: data_dir: ./train_data/ label_file_list: - ./train_data/data/Label.txt . . loader: **batch_size_per_card: 2** . . Eval: dataset: data_dir: ./train_data/ label_file_list: - ./train_data/data/Label.txt -
執行訓練指令
# 沒有checkpoint python tools/train.py -c ./pretrain_models/en_PP-OCRv3_det_distill_train/config.yml -
輸出模型
# 輸出模型 python tools/export_model.py -c ./pretrain_models/en_PP-OCRv3_det_distill_train/config.yml -o Global.checkpoints="./output/ch_PP-OCR_V3_det/best_accuracy" Global.load_static_weights=False Global.save_inference_dir="./inference/det/"
建立 Rec 訓練設定
-
點擊此連結。下載預訓練模型。
- 這邊下載
en_PP-OCRv3_rec模型。config檔案參照ch_PP-OCRv3_rec_distillation.yml。
- 這邊下載
-
配置模型以及config路徑。
. └── pretrain_models ── rec ── en_PP-OCRv3_rec_train ├── best_accuracy.pdopt ├── best_accuracy.pdparams ├── best_accuracy.states ├── train.log └── config.yml -
調整
config.yml內容Global: pretrained_model: ./pretrain_models/en_PP-OCRv3_rec_train/best_accuracy character_dict_path: ppocr/utils/ic15_dict.txt character_type: en max_text_length: 10 . . Architecture: Head: head_list: - SARHead: max_text_length: 10 . . Train: dataset: data_dir: ./train_data/data/ label_file_list: - ./train_data/data/rec_gt.txt transforms: - RecConAug: max_text_length: 10 . . loader: batch_size_per_card: 2 Eval: dataset: data_dir: ./train_data/data/ label_file_list: - ./train_data/data/rec_gt.txt . . loader: batch_size_per_card: 1 num_workers: 1 -
執行訓練指令
# 沒有checkpoint python tools/train.py -c ./pretrain_models/en_PP-OCRv3_rec_train/config.yml -
輸出模型
# 輸出模型 python tools/export_model.py -c ./pretrain_models/en_PP-OCRv3_rec_train/config.yml -o Global.checkpoints="./output/v3_en_mobile/best_accuracy" Global.save_inference_dir="./inference/rec/"
Inference with webcam
from paddleocr import PaddleOCR
import cv2
import numpy as np
ocr = PaddleOCR(
det_model_dir='./inference/det' ,
rec_model_dir = './inference/rec'
)
cap = cv2.VideoCapture(0)
while(True):
_, frame = cap.read()
results = ocr.ocr(frame)
for result in results[0]:
pts = np.array(result[0], np.int32).reshape((-1,1,2))
cv2.polylines(frame,[pts],True,(0,255,0))
cv2.putText(
img=frame,
text=result[1][0],
org=(int(result[0][3][0]),int(result[0][3][1])),
fontFace=cv2.FONT_HERSHEY_DUPLEX,
fontScale=0.5,
color=(0, 0, 255),
thickness=1,
lineType=cv2.LINE_AA
)
cv2.imshow('frame', frame)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cap.release()
cv2.destroyAllWindows()